
The Quest for a NoSQL Database Implementation
Published Feb 26, 2019
In the past few weeks, I have been experimenting with my own NoSQL database, a key-value data store to be precise. And I have realized how simple it’s to create, at least a non-distributed one. Ok, ok, you may argue that this is the distinguishing characteristic of a NoSQL database, but I have learned so much from this simple and fun project, and to honest it’s so amazing that I couldn’t resist writing a post about it, so here we go.
What we are going to build is a key-value persistent database that (mostly) adheres to the ACID properties. If you don’t know what are these properties, stick around we will shortly know. Enough talk let’s get going.
An Immutable Binary-Search Tree
When solving a problem, specially a big problem, I like to start with a simpler version of the problem, so first, we will begin with an in-memory key-value store. Yes, it’s a simple dictionary but we won’t use a hash table because a hash table isn’t easy to store and be partly load into memory from a file. What we will use is a binary-search tree. A binary-search tree can be divided into standalone nodes, which is nice to have. We will soon see why. I’m going to use an immutable implementation of the binary-search tree data structure, it will help us later when we need to store the database, and you will see how easy it’s to implement
An immutable binary-search tree means that each time we modify a node we create a copy of the current tree with the modified node. But since the trees are immutable, we can reuse some parts of the previous tree without fear of it being modified, and only copy the part of the tree that connects from tree’s root to the modified node. For example if we have a tree that look like this
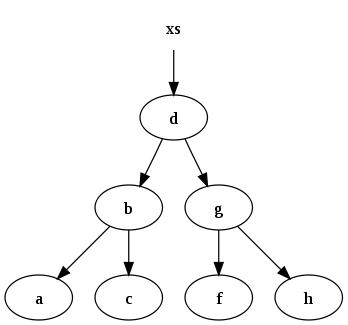
then if we insert node e into the tree by creating a copy, we only need to copy four nodes.
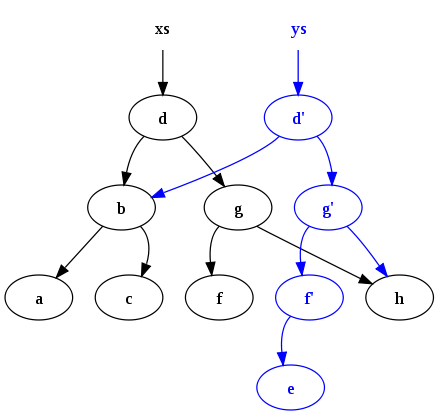
becuase the rest of the tree wasn’t modified we don’t need to copy it nor do we worry about the previous tree modifying its nodes, because it’s immutable.
Let’s write the node class, and the binary tree constructor
class Node:
def __init__(self, key, value, left, right):
self.key = key
self.value = value
self.left = left
self.right = right
class BinaryTree:
def __init__(self):
self._root = None
next we will define the get operation in the binary tree class
def get(self, key):
return self._get(self._root, key)
def _get(self, node, key):
if node is None:
return None # Not found
elif key == node.key:
return node.value
elif key > node.key:
return self._get(node.right, key)
else:
return self._get(node.left, key)
and the set operation
def set(self, key, value):
self._root = self._set(self._root, key, value)
def _set(self, node, key, value):
if node is None:
return Node(key, value, None, None)
elif key == node.key:
return Node(key, value, node.left, node.right)
elif key > node.key:
return Node(node.key, node.value,
node.left, self._set(node.right, key, value))
else:
return Node(node.key, node.value,
self._set(node.left, key, value), node.right)
finally the delete operation
def delete(self, key):
self._root = self._delete(self._root, key)
def _delete(self, node, key):
if node is None:
raise KeyError("Key not found")
elif key == node.key:
if node.left is not None or node.right is not None:
return self.merge(node.left, node.right)
else:
return None
elif key > node.key:
return Node(node.key, node.value,
node.left, self._delete(node.right, key))
else:
return Node(node.key, node.value,
self._delete(node.left, key), node.right)
to delete a node, we need to merge it’s left and right nodes. First we determine the highest key in the left subtree, then we move it to the place of the node we wish to delete. This we it’s guaranteed that this replacement node will be larger than the left node and smaller than the right node.
if only a left or right node exists, it simply becomes the replacement for the deleted node.
if neither left or right node exists, we just delete the node.
def merge(self, left, right):
new_node = None
if left is not None and right_ref is not None:
left_max = self._get_max(left)
new_left = self._delete(left, left_max.key)
new_node = Node(left_max.key, left_max.value,
new_left, right)
elif left_ref is not None:
new_node = Node(left.key, left.value,
left.left, left.right)
elif right_ref is not None:
new_node = Node(right.key, right.value,
right.left, right.right)
return new_node
def _get_max(self, node):
while node.right is not None:
node = node.right
return node
With this in place we can start implementing the ACID properties. We won’t go in order but we will cover them all
Durability
Durability is the property that a committed database transaction (a set of related modification to the database that should be treated as a indivisible bundle) is never lost, even if a failure happens after committing or the application was closed.
To achieve this, we need to store our current database (the binary-search tree) in a file and guarantee that a committed transaction is completely written in the database file such that even if the computer shut down unexpectedly we won’t lose our database.
Next, we need to specify how the binary-search tree is stored in the file. Some of the properties we need are:
- being able to store parts of the tree. Since a modification to the tree only copies a small portion of the unmodified tree, storing the whole tree on each commit would be a waste of space and time.
- being able to load parts of the tree. Loading the whole database at once in memory is both time and space consuming. And if big values are stored in the tree they also need to be loaded even if they aren’t used. So we need to be able to load a few nodes only
- being able to locate the root in the database. The root is the fundamental block of the tree, without it we can’t even dream of knowing what, or where are the rest of the tree. If we deleted the tree we lose everything including the root, and we won’t be able to load the tree from the file because we don’t know where the root is in the file
To store parts of a tree, that means each part of a tree can be stored in a different location in the file. If you have used C or similar languages, a node class implementation would use pointers to locate the left and right nodes. A pointer is simply a location in memory. We will use the same trick here, each stored value will get an address (the pointer) that can be used to reference the value in the file. That means we will use our file storage like a memory with addresses.
If a node knows the address of it’s left and right nodes it can load them into memory easily but it also means that to store a node all the nodes it references directly or indirectly needs to be stored first. This is not a problem, but something to keep in mind.
This also solves the problem of loading parts of the tree, though partially. What happens when we load a node that it’s left or right node is not loaded? We said that when storing a node we only store it’s left and right nodes using a pointer in C.
We will do something similar. We don’t need to load the full tree to be able to access it. We will represent a node in two ways, either the current representation, we will call it it’s value (very imaginative) which has the normal fields of a node (key, value, left, right), or using an int which is a pointer to the node in the database file. This way we don’t need to load the full tree, because a node can be represented by a number.
We will use this value-address pair to represent a value too. Even if we loaded a node we don’t need it’s value most of the time. So we won’t load the value until it’s needed.
Lastly, we need to be able to locate the root in the database. This is simple, we use a pointer stored at the beginning of the file that points to the location of the root, that way when we need to get the root, we read the pointer at the beginning of the file, then we seek to where that pointer leads us in the file, lastly we read the root node.
To implement this we will use the struct package provided by python standard library. We will use it to convert a python int to a fixed size int (8 bytes) or vice-versa.
We will start with some helpers
class Storage:
# > means big-endian order (network order), std. size and alignment
# Q means Unsigned long long
INTEGER_FORMAT = ">Q"
# the standard size of unsigned long long
INTEGER_SIZE = 8
# root address is stored at the beginning of the file
# the root block is 8 bytes in size
ROOT_BLOCK_SIZE = 8
def __init__(self, file):
self._file = file
self._ensure_root_block()
def _ensure_root_block(self):
self._file.seek(0, os.SEEK_END)
if self._file.tell() >= self.ROOT_BLOCK_SIZE:
# root block exists. No further actions needed
return
self._file.seek(0)
self._file.write(b'\x00' * self.ROOT_BLOCK_SIZE) # writes 0
def _write_int(self, integer):
bytes = struct.pack(self.INTEGER_FORMAT, integer)
self._file.write(bytes)
def _read_int(self):
bytes = self._file.read(self.INTEGER_SIZE)
return struct.unpack(self.INTEGER_FORMAT, bytes)[0]
Data is always written at the end of the file, but honestly it doesn’t matter, all that matters is we write the data in a place that is not used, and the end of the file seemed like a good solution.
Right before storing the data we write it’s size so that when reading we know how many bytes we should read.
def write(self, data):
self._file.seek(0, os.SEEK_END)
address = self._file.tell()
self._write_int(len(data))
self._file.write(data)
return address
given an address we can read the data
def read(self, address):
self._file.seek(address)
length = self._read_int()
data = self._file.read(length)
return data
lastly some methods to write and read the root address
def write_root_address(self, address):
self._file.seek(0)
self._write_int(address)
def read_root_address(self):
self._file.seek(0)
address = self._read_int()
if address == 0:
return None
return address
As we said previously, we will use two representation of the values stored in the database (whether it be a node’s value or the node itself). Thus we write a class for it.
We will need to be able to serialize (convert to bytes) the value and load/de-serialize the read bytes when writing and reading from the Storage class. For this we will use the pickle package provided by the python standard library
class ValueRef:
def __init__(self, value=None, address=None):
self.value, self.address = value, address
def serialize(self):
return pickle.dumps(self.value)
def load(self, bytes):
self.value = pickle.loads(bytes)
and the node and it’s ValueRef class becomes
class Node:
def __init__(self, key, value_ref, left_ref, right_ref):
self.key = key
...
class NodeRef(ValueRef):
def serialize(self):
return pickle.dumps((
self.value.key, self.value.value_ref.address,
self.value.left_ref.address if self.value.left_ref else None,
self.value.right_ref.address if self.value.right_ref else None
))
def load(self, bytes):
key, value_addr, left_addr, right_addr = pickle.loads(bytes)
left_ref = NodeRef(address=left_addr) if left_addr else None
right_ref = NodeRef(address=right_addr) if right_addr else None
self.value = Node(key, ValueRef(address=value_addr), left_ref, right_ref)
Now all that’s left is to use this in the tree class. I want to maintain a good decoupling, so we will use an abstract class that is responsible of linking the tree with the storage, and the tree class will inherent it. We want to separate the in memory representation of the database from the storage representation and to decouple them greatly, that way even if we decided to use a different implementation of the in memory representation, we don’t modify the code much.
class LogicalBase:
RootRefClass = None # implemented in BinaryTree class
def __init__(self, storage):
self._storage = storage
self._root_ref = None
def _retrieve_root(self):
address = self._storage.read_root_address()
if address is None:
self._root_ref = None
return
if self._root_ref and self._root_ref.address == address:
return
self._root_ref = self.RootRefClass(address=address)
self._root_ref.load(self._storage.read(address))
def _retrieve(self, value_ref):
if value_ref is None or value_ref.value is not None:
# value is already loaded in memory
return value_ref
bytes = self._storage.read(value_ref.address)
value_ref.load(bytes)
return value_ref
def _store_value_ref(self, value_ref):
if value_ref.address is not None:
# value is already stored in memory
return
address = self._storage.write(value_ref.serialize())
value_ref.address = address
with this in place let’s continue with the integration of the binary tree class and logical base.
logical base will define five basic operations, getting a value, setting a value, deleting a value, and committing the changes, or rolling them back. The way these operations will be carried out is the responsibility of the binary tree class.
class LogicalBase:
...
def get(self, key):
if self._root_ref is None:
self._retrieve_root()
value_ref = self._retrieve(self._get(self._root_ref, key))
if value_ref is None:
return None
return value_ref.value
def set(self, key, value):
if self._root_ref is None:
self._retrieve_root()
self._root_ref = self._set(self._root_ref, key, ValueRef(value=value))
def delete(self, key):
if self._root_ref is None:
self._retrieve_root()
try:
self._root_ref = self._delete(self._root_ref, key)
except KeyError:
return False
return True
def commit(self):
if self._root_ref is not None and self._root_ref.address is None:
self._prepare_to_store(self._root_ref)
self._storage.write_root_address(self._root_ref.address)
self._root_ref = None
def rollback(self):
self._root_ref = None
Next to the BinaryTree class
class BinaryTree(LogicalBase):
RootRefClass = NodeRef
def _prepare_to_store(self, node_ref):
if node_ref is None or node_ref.address is not None:
return
self._prepare_to_store(node_ref.value.left_ref)
self._prepare_to_store(node_ref.value.right_ref)
self._store_value_ref(node_ref.value.value_ref)
self._store_value_ref(node_ref)
for the rest we only need to change a two things.
First, when returning from a _get, _set or _delete we return a NodeRef with it’s value set to the node we were returning in the previous implementation.
Secondly, when calling these functions we retrieve the value of the node_ref using the _retrieve method we defined earlier.
And that’s it! Our database is durable now, and we can store values without fear of loss.
Isolation
As our database stands now, it can be everywhere at the same time.
Suppose that two processes are using the same database. Process A modifies the database at the same time process B modifies it, if you think about it the last process to commit it’s changes completely overrides the other process’s changes. Because once a transaction begins, the root_ref is not updated from the database file until a commit is issued and the root_ref is written to the database.
What we need to happen is to restrict access to the database until the first process commits it’s changes and releases the database for the other process’s use.
We will use a lock to achieve this. A lock is acquired when a database change need to be done and only released when the changes are committed back to the database.
We also need not to restrict reading from the database when another process is changing the database.
As it turns out this is simple to implement. All we need is a lock on the database file to restrict writing to it when another process is writing too, but when reading we don’t care about the lock and pass it to the database. The other thing we need to take care of is the root address. Since the root address is stored in one place, thus it’s mutable and needs more care. Unlike the rest of the database, when reading or writing the root address we need to lock the root address portion, because if a read happens while the root address is being written we can end up with a messed up address.
So let’s dive into code.
To implement the locks we will use a library called portalocker. It’s very simple to use. To lock a file all we need to do is call portalocker.lock(file, portalocker.LOCK_EX) and to unlock it we call portalocker.unlock(file). The LOCK_EX means that the lock is exclusive, that is it can’t be acquired by another process.
After installing portalocker, we will implement an interface for it in the storage class to lock the storage, unlock it, lock the root section and unlock it.
class Storage:
def __init__(self, file):
try:
self._root_lock_file = open('.'+file.name + '.lock', 'x+b')
except:
self._root_lock_file = open('.'+file.name + '.lock', 'r+b')
...
def read_root_address(self):
self.lock_root()
...
self.unlock_root()
def write_root_address(self):
self.lock_root()
...
self.unlock_root()
def lock(self):
self._locked = True
portalocker.lock(self._file, portalocker.LOCK_EX)
def unlock(self):
self._locked = False
self._file.flush()
portalocker.unlock(self._file)
def lock_root(self):
portalocker.lock(self._root_lock_file, portalocker.LOCK_EX)
def unlock_root(self):
portalocker.unlock(self._root_lock_file)
with the interface in place, we can start implementing the lock mechanism in the LogicalBase class.
We just need to lock the storage when setting a value or deleting it, and lock the root section when reading or writing to it. The root section can be unlocked immediately once the root address is read or written to, but the database lock can only be unlocked when committing or rolling back a transaction.
class LogicalBase:
def get(self, key):
if not self._storage.is_locked(): # inplace of if self._root_ref is None:
self._retrieve_root() # we don't lock the database
...
def set(self, key, value):
if not self._storage.is_locked(): # inplace of if self._root_ref is None:
self._storage.lock()
...
def delete(self, key):
if not self._storage.is_locked(): # inplace of if self._root_ref is None:
self._storage.lock()
...
def commit(self):
...
self._storage.unlock()
def rollback(self):
...
self._storage.unlock()
and with these simple changes we have implemented our isolation property.
Atomicity
Atomicity may be the most important property of the ACID properties. It’s the guarantee that a transaction is either successfully committed or not at all. Put in other words if a failure happens during committing the transaction is discarded if it can’t be fully completed.
And here’s the great thing, our implementation already meets these requirements. First, A transaction doesn’t affect the database until it’s committed. When committing a transaction, we do affect the database file, so if a failure happens, the database file will have additional data, but this data doesn’t really affect the database when loaded, because the reachable keys remain the same until we change the root address. Thanks to the immutable nature of our tree and database.
Consistency
I don’t intend to implement this in our little database, but it deserves to be mentioned.
The consistency property can be implemented by the user of the database or by extending our logical base to run other checks before committing to the database. What checks it will run depends on what we want to achieve, but we need to store these checks somewhere where we could always retrieve it, Wondering where it can be stored? We can use what we already built and use special keys to store the kind of checks we want to perform. We may store it in the same database file or in a different one.
Improvements
There’s a plenty of room for improvements in this simple key-value database. I will mention a few examples for the sake of completeness.
First and most importantly this database doesn’t scale well. Try adding the keys [i for i in range(10**5)] in order, and notice how slow it becomes specially for setting a value or deleting it. This happens because of an in-balanced tree; all the keys are added to the right subtree of each node and all the left nodes are empty making the tree’s access time O(n). There’s many ways to solve this, we can rebalance the tree, or a better approach would be to use some kind of a self-balancing tree.
Second comes the isolation property, and this is an easy fix. The isolation property implementation in a database can be characterized by it’s level. There’s four levels of isolation a database can implement. The wikipedia page on isolation does a great job explaining the different levels and their effects on the database transactions.
Our little database system here implements the read committed level of isolation, but can easily be upgraded to use serializable level of isolation without locking the database. By not updating the root_ref on get operations and only update it when beginning a transaction. We will need to add two methods to begin and end a read transaction. Interleaving get and set/delete operations during such a transaction will get a little tricky but doable.
Another appoach is to do transactions in a completely different way. The idea of Redis transactions is a powerful yet simple way to do it. All operations are delayed until commit (or EXEC in Redis) is issued. Only then, the operations are performed. This is useful for performance and when the database is a distributed system.
Lastly the value attached with a key as it’s now is a simple picklable value, but we can easily implement more complex values. Here’s a few examples from Redis database (an in-memory key-value store):
- List: Easiest to implement as a linked list, but that in itself is a very powerful structure. Support adding and poping from both ends and you’ve got a stack and queue at your disposal.
- Map: Could be implemented as a hash table but it’s easier to implement as a tree, which we already support.
- Ordered and Unordered Set: Again you may use what we’ve already built.
Scalability
Scalability is a system’s ability to handle a growing amount of work. In the database system case, the growing amount of work represents a growth in data stored.
There’s two types of scaling in database systems, vertical scaling and horizontal scaling.
A vertical scaling is when a database is scaled by adding more resources to the existing hardware, like more RAM, storage, or processing power. Horizontal scaling is done by adding more hardware units, by adding more processing units and distributing the workload amongst them.
Horizontal scaling is way cheaper than vertical scaling which makes it more desirable. A unique characteristic of NoSQL databases is there ability to scale exteremely well horizontally.
To scale our little database horizontally, we could follow many approaches. We could have a coordinator server that determines where in a cluster of servers a key resides. To not have to save all the keys, this server will maintain a key-range to server mapping. Each server will maintain it’s own database file, unaware of other servers.
From here on things will get more and more tricky. We will need to have replicas of data, while ensuring they are up-to-date with each other and maintaining the ACID properties. NoSQL databases’ answer to this is to drop or implement some kind of more relaxed ACID properties. These relaxed properties has became their own and were named the BASE properties.
The End
And that’s it. Thanks for reading. I hope you have learned something out of this and enjoyed reading it as much as I enjoyed writing it. See you soon!